
AIによる画像生成や編集は日々進化しています。その中でも ComfyUI はノードベースで直感的にワークフローを構築できる人気ツールです。
今回利用する Qwen Image Edit は、Alibaba Cloud(アリババクラウド)が開発した Qwenシリーズ の一部で、テキストによる指示をもとに画像を柔軟に編集できるモデルです。文字やUI要素の削除、背景の変更、キャラクターの追加など幅広い編集に対応しており、生成結果の「自然さ」や「一貫性」に優れている点が大きな特徴です。
さらに、本記事で紹介する GGUF版 は軽量化・最適化されているため、GPUリソースの限られた環境でも効率よく動作します。これにより、クラウド環境(Paperspace Gradientなど)上でも一貫した結果を安定的に得ることができます。
今回は、この Qwen Image Edit (GGUF版) をPaperspace Gradient上に導入し、ComfyUIを使って画像編集や複数画像の結合を行う方法を解説します。
Step 0: Paperspace Gradientで環境構築とモデルダウンロード
まず、Paperspace Gradient上で環境を準備します。基本的な方法は以前の記事と同じですが、Qwen Image Edit用のモデルをダウンロードします。大きいモデルだとVRAMが足りない(と思う)のでGGUFバージョンを使います。
Hugging faceのリポジトリの説明に従い、所定の位置にモデルをダウンロードします。
# Qwen Image Edit (GGUF版) モデルをダウンロード
!wget -L -O /tmp/ComfyUI/models/vae/Qwen_Image-VAE.safetensors "https://huggingface.co/QuantStack/Qwen-Image-Edit-GGUF/resolve/main/VAE/Qwen_Image-VAE.safetensors"
!wget -L -O /tmp/ComfyUI/models/text_encoders/Qwen2.5-VL-7B-Instruct-mmproj-BF16.gguf "https://huggingface.co/QuantStack/Qwen-Image-Edit-GGUF/resolve/main/mmproj/Qwen2.5-VL-7B-Instruct-mmproj-BF16.gguf"
!wget -L -O /tmp/ComfyUI/models/text_encoders/Qwen2.5-VL-7B-Instruct-Q4_K_S.gguf "https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-Q4_K_S.gguf"
!wget -L -O /tmp/ComfyUI/models/unet/Qwen_Image_Edit-Q4_K_S.gguf "https://huggingface.co/QuantStack/Qwen-Image-Edit-GGUF/resolve/main/Qwen_Image_Edit-Q4_K_S.gguf"
また、ComfyUIでGGUFを使うので、以下の方法でノードをダウンロードしておきます。
# ComfyUI の custom_nodes 配下へ
%cd /tmp/ComfyUI/custom_nodes
# GGUF ローダ(LoaderGGUF)のダウンロード
!git clone https://github.com/city96/ComfyUI-GGUF.git
!pip install --upgrade gguf
Step 1: ComfyUIでQwen Image Edit (GGUF版) を読み込む
Paperspace上にモデルを配置できたら、ComfyUIのテンプレートにある「Qwen image edit」ワークフローを開き、ノードを差し替えます。
まずはテンプレートの検索で「qwen」と入力しQwen Image Editを選びます。

テンプレートを選んだ直後は以下のようなワークフローが表示されます。赤枠が今回変更する部分です。
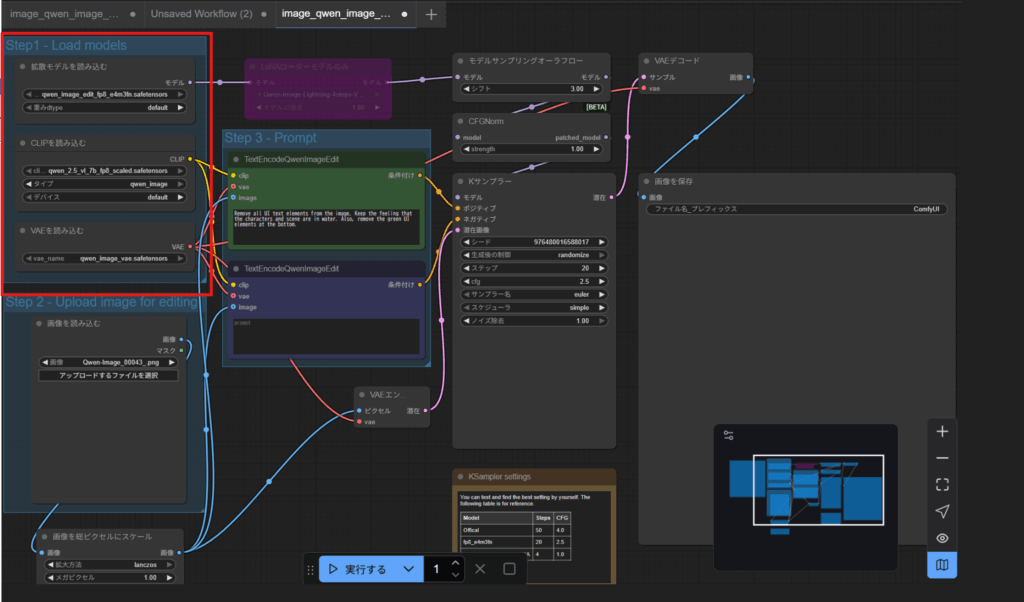
上記でノードの追加がうまくできていれば、「ノードを追加」で以下のようにGGUFを読みこむ項目があると思います。
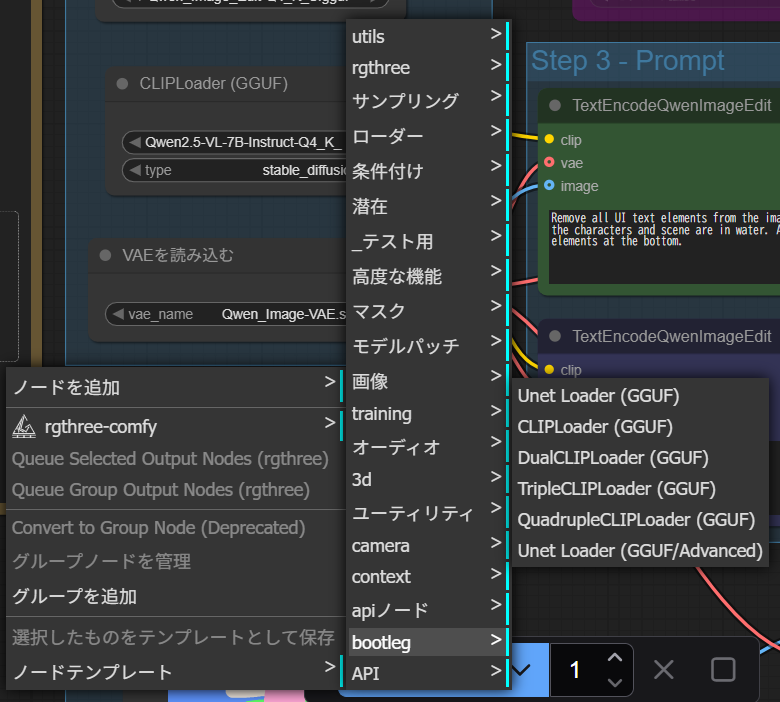
元々のノードを以下のように差し替えます。接続は元のワークフローと同じです。
- 「拡散モデルを読みこむ」⇒「Unet Loader(GGUF)」
- 「CLIPモデルを読みこむ」⇒ 「CLIP Loader(GGUF)」
これで、ComfyUIはGGUF版の軽量モデルを利用して編集処理を実行できます。ノードを差し替えた後は、以下のようになります。

Step 2: 画像をアップロードしてプロンプトを入力
- 「画像を読み込む」ノード に対象画像を入力
- 「TextEncodeQwenImageEdit」ノード にプロンプトを入力
例:
Remove all UI text elements from the image.
Keep the feeling that the characters and scene are in water.
Also, remove the green UI elements at the bottom.
上下二箇所にプロンプトの入力ができますが、上はプロンプト、下はネガティブプロンプトみたいです。
Step 3: 画像生成
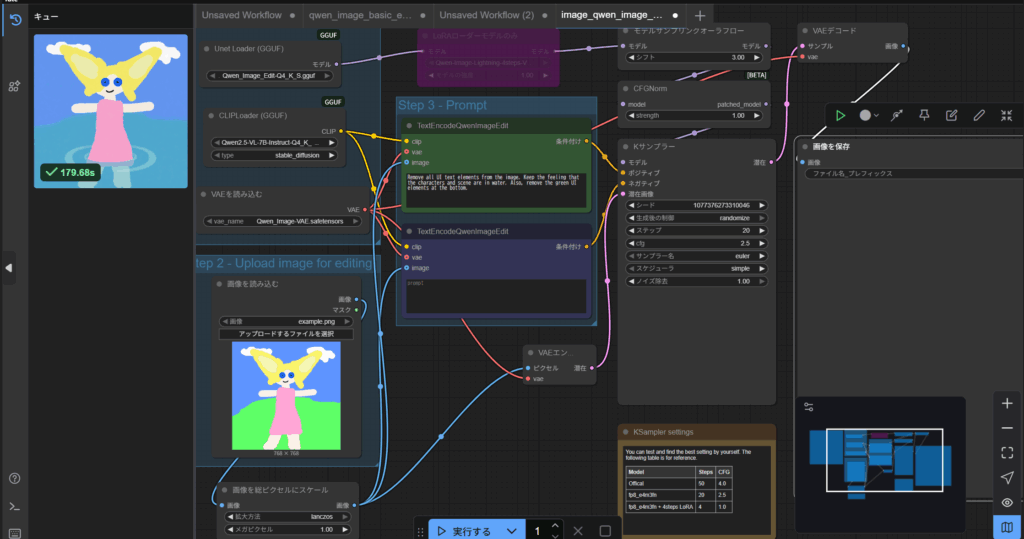
画像とプロンプトをいれたら、実行します。数分で画像が生成されます。以下の画像はテンプレートのサンプルをGGUFに置き換えたうえでそのまま実行しただけです。中心のキャラクターを維持しつつ、画像の背景はプロンプトの指示通りに変換されています。
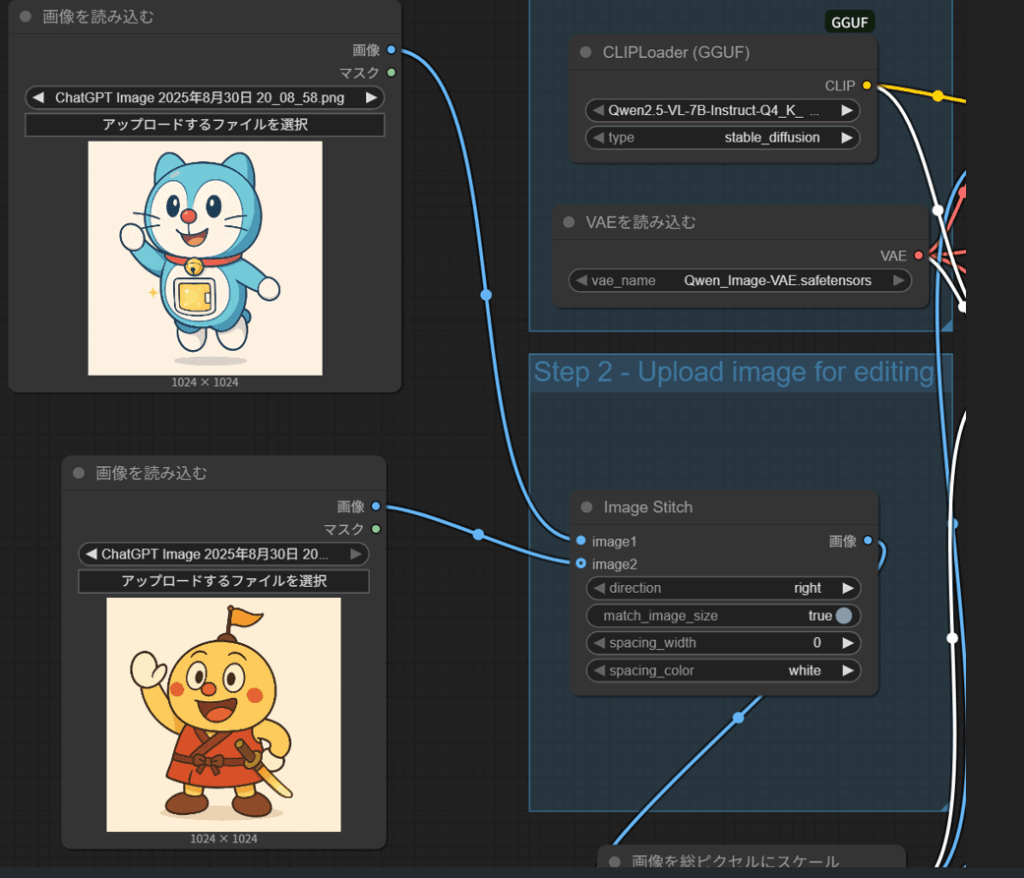
Step 4: 画像を結合(Image Stitchノード)
応用として、2枚の画像を横に並べることもできます。
- 画像を読み込むノードを2つ用意
- Image Stitchノード に接続
direction = right(横に結合)match_image_size = true(自動リサイズ)spacing_width = 0(余白なし)
以下のようになります。
これにより、キャラクターを並べたり、複数イラストを1枚にまとめられます。任意の服を着せたり、2つのキャラクターを同じ空間に同居させたりできるみたいです。テキトーにプロンプトを入力すると以下のような画像が得られます。
画像のサイズのバランスなどが重要らしいですが、ChatGPTで生成した画像であれば画像のサイズが揃うと思うので、比較的コントロールしやすいのかもしれません。

Hailuoで動画にしてみる。
まとめ
今回の流れをまとめると:
- Paperspace GradientのNotebookでQwen Image Edit (GGUF版) モデルをダウンロード
- ComfyUIで Qwen Image Editのテンプレートを読み込み、GGUF用にノードを変更
- 入力画像を読み込みプロンプトで編集
- Image Stitchを用いることで画像結合し、2つのキャラクターの画像生成
これにより、再現性のあるクラウド環境で効率的に画像編集・結合が行えるようになります。
※本記事は、人工知能が生成したものを編集して作成しました。

コメント