はじめに
大規模言語モデルの発展が早すぎて,何を追えば良いのか分からなくなってきた.なので,新しいモデルの登場頻度が落ち着いてから遊ぼうと思っていたが,独自の学習データを用いた機能特化モデルを今後作成したいと思ったので,ひとまず大規模言語モデルの使い方を確認してみた.
調べてみたら,Vicuna-13bがオープンになっているモデルの中では軽量かつ性能が高いみたいなので,ひとまずこれで遊んでみる.今回使用したモデルは,Vicuna-13Bを量子化することで使用するGPUメモリを削減したvicuna-13b-GPTQ-4bit-128gである.通常版だと60GBのGPUメモリが必要らしい.
Google Colab上で動くコードは発見したので,Paperspaceへの移植の方法の勉強がてら,Paperspace Gradient上で動くようにしてみる.
ベースとなるGoogle Colab用のコードは,以下に記載してあるコードである.
環境
・Win10 PC
・Google Chrome
・Paperspace Gradient Pro (使用したGPUはFree-P5000.VRAMが8GB以上を要求され,16GBのこれじゃないと動作しなかった)
方法
Google Colab上では動いた上記のコードを,Paperspace Gradient上で記述し実行しても,エラーが出て実行ができなかった.
pip freeze でGoogle Colab上のpipのパッケージを出力して,それらをすべてPaperspace Gradient上でインストールしてみたりもしたが,そこまではやる必要はなかった.
実行できなかった原因は, (1)gdalやaria2がインストールできていなかったことと,(2)quant.py内で「quant_cuda」モジュールがインポートできていなかったことだったので,それらを改変したコードを作成した.
なお,Paperspace Gradientの場合,重いファイルをnotebookにダウンロードすると課金されるので,すべて「/tmp」ディレクトリ上で実行した.
まずは下記のセルを記述して,githubから必要なコードを取得するとともに,aria2とgdalをインストールする.
%cd /tmp
# aria2のインストール
!apt-get update
!apt-get -y install -qq aria2
#gdalのインストール
!add-apt-repository -y ppa:ubuntugis/ppa
!apt-get update
!apt-get -y install gdal-bin libgdal-dev
!git clone -b v1.0 https://github.com/camenduru/text-generation-webui
%cd /tmp/text-generation-webui
!pip install -r requirements.txt
!mkdir /tmp/text-generation-webui/repositories
%cd /tmp/text-generation-webui/repositories
!git clone -b v1.0 https://github.com/camenduru/GPTQ-for-LLaMa.git
%cd GPTQ-for-LLaMaその後,quant.pyを修正して,上書きする.なお,quant.pyのコードをコピペした後に,.pyファイルを作成するために「%%file quant.py」を追記し,さらに3行(「修正箇所」とコメントがある箇所)を追記しただけである.
%%file quant.py
import numpy as np
import torch
import torch.nn as nn
import math
import site #修正箇所
site.addsitedir("/usr/lib/python3.9/site-packages/") #修正箇所
import quant_cuda #修正箇所
def quantize(x, scale, zero, maxq):
if maxq < 0:
return (x > scale / 2).float() * scale + (x < zero / 2).float() * zero
q = torch.clamp(torch.round(x / scale) + zero, 0, maxq)
return scale * (q - zero)
以下省略
上書きは以下のコードで行う。
%mv quant.py /tmp/text-generation-webui/repositories/GPTQ-for-LLaMaそして,以下のコードで,「quant_cuda」モジュールの作成,モデルのダウンロード,Gradioの起動を行う.
%cd /tmp/text-generation-webui/repositories/GPTQ-for-LLaMa
# モジュールの作成
!python setup_cuda.py install
# modelのダウンロード
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/raw/main/config.json -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/raw/main/generation_config.json -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o generation_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/raw/main/special_tokens_map.json -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o special_tokens_map.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/resolve/main/tokenizer.model -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o tokenizer.model
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/raw/main/tokenizer_config.json -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o tokenizer_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/vicuna-13b-GPTQ-4bit-128g/resolve/main/vicuna-13b-4bit-128g.safetensors -d /tmp/text-generation-webui/models/vicuna-13b-GPTQ-4bit-128g -o vicuna-13b-4bit-128g.safetensors
# gradioの実行
%cd /tmp/text-generation-webui
!python server.py --share --chat --wbits 4 --groupsize 128
ちなみに,IDとパスワードを記入したファイル(中身は,”ID(任意):password(任意)“とする)を作成した後,以下のように実行すればパスワードとIDをgradioに付けられる.今回はwebui_passというファイルを作成した.タダ乗りが気になれば,設定した方が良い.
!python server.py --share --chat --wbits 4 --groupsize 128 --gradio-auth-path /notebooks/webui_passコマンドライン引数のリストはこのサイトのStarting the web UIの項目に記載がある.
動作
とりあえず会話はできている.なんかGenerateを押しても動かない時があるので,その時はGradioを再起動したりする.

その他(パラメータについて)
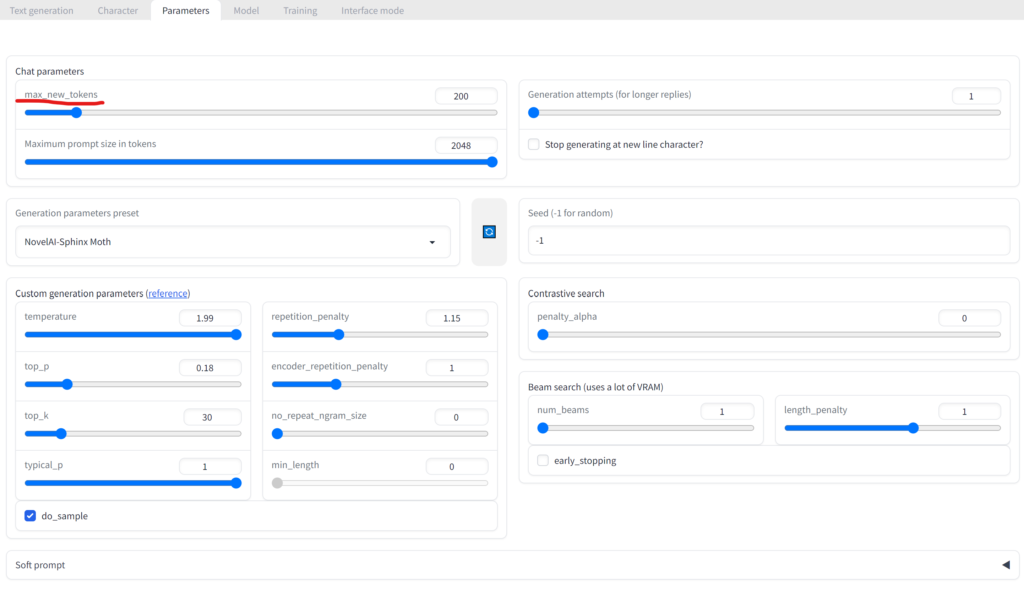
生成される文章が短いと思っていたら,色々パラメータをいじれることが分かった.例えば,Parametersタブのmax_new_tokensの値を大きくすると,AIが生成する文章が長くなったりした.
まとめ
とりあえず無理やり動かせた.Paperspaceへの移植の際は,Google Colab上でpip freezeしてモジュールのリストを抽出することも有効だと思われるので,今後使っていきたい.
何をもってGPT4の90%の性能と言ってるのかは知らないけど,とりあえず手元にモデルをダウンロードして実行できたので,色々と組み込んだりして応用できそう.

コメント