はじめに
Text2Video-Zeroのコードが公開されていたので,テキストから動画を生成するText to Videoで遊んでみた.Hugging Faceのリポジトリを指定することで,色々なモデルを使えるようにした.
Text2Video-ZeroのGithubリポジトリ
https://github.com/Picsart-AI-Research/Text2Video-Zero
また,Text2Video-Zeroで動画を生成した後に,FILMでフレーム間の補間を行ってみた.
環境
・Win10 PC
・Google Chrome
・Papaerspace Gradient Growth (今回はA6000を使用.ただ,VRAMが16GB以上あれば動きそう VRAMを削減するパラメータchunk_sizeを設定すれば,恐らくP5000でも動く.ColabのT4でも動いた.)
方法
基本的には上記のGitHubに沿うだけである.
まずはリポジトリのクローンして,ライブラリをインストールする.
%cd /tmp
!git clone https://github.com/Picsart-AI-Research/Text2Video-Zero.git
%cd Text2Video-Zero/
!pip install -r requirements.txtmodel.pyを書き換える.model.pyをコピペして,process_text2video関数を以下のように書き換える.下記のコードの最初にある「%%file model.py」でファイルを生成して,model.pyを上書きしている.
※以下のコードでchunk_size=2などとすれば,VRAMが削減できる.Text2Video-Zeroの「Low Memory Inference」の項目を参照.
%%file model.py
from enum import Enum
import gc
import numpy as np
import tomesd
import torch
~~省略~~
def process_text2video(self, prompt,model_name,added_prompt,negative_prompts,guidance_scale,num_inference_steps,path,fps,t0,t1,motion_field_strength_x,motion_field_strength_y,video_length,chunk_size=8,watermark='Picsart AI Research',merging_ratio=0.0,seed=-1,
resolution=512,use_cf_attn=True,use_motion_field=True,smooth_bg=False,smooth_bg_strength=0.4):
print("Module Text2Video")
if self.model_type != ModelType.Text2Video or model_name != self.model_name:
print("Model update")
unet = UNet2DConditionModel.from_pretrained(
model_name, subfolder="unet")
self.set_model(ModelType.Text2Video,
model_id=model_name, unet=unet)
self.pipe.scheduler = DDIMScheduler.from_config(
self.pipe.scheduler.config)
if use_cf_attn:
self.pipe.unet.set_attn_processor(
processor=self.text2video_attn_proc)
self.generator.manual_seed(seed)
# added_prompt = "masterpiece, best quality, masterpiece"
# negative_prompts = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer difits, cropped, worst quality, low quality, deformed body, bloated, ugly, unrealistic'
prompt = prompt.rstrip()
if len(prompt) > 0 and (prompt[-1] == "," or prompt[-1] == "."):
prompt = prompt.rstrip()[:-1]
prompt = prompt.rstrip()
prompt = prompt + ", "+added_prompt
# if len(n_prompt) > 0:
# negative_prompt = n_prompt
# else:
# negative_prompt = None
result = self.inference(prompt=prompt,
video_length=video_length,
height=resolution,
width=resolution,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
guidance_stop_step=1.0,
t0=t0,
t1=t1,
motion_field_strength_x=motion_field_strength_x,
motion_field_strength_y=motion_field_strength_y,
use_motion_field=use_motion_field,
smooth_bg=smooth_bg,
smooth_bg_strength=smooth_bg_strength,
seed=seed,
output_type='numpy',
negative_prompt=negative_prompts,
merging_ratio=merging_ratio,
split_to_chunks=True,
chunk_size=chunk_size #ここをchunk_size=2とするとVRAMが削減される(2以上でもOK).
)
return utils.create_video(result, fps, path=path, watermark=None)
その後,以下のコードを実行して動画を生成する.
プロンプトやネガティブプロンプト,モデルのリポジトリの指定などは,以下のコードの変数を変更する.パラメータ(サンプリングステップ数,動画の時間やFPSなど)も設定する.ただ,少しパラメータをいじった感じだと,結局のところdefaultの値が一番良さそう.調整して良いのは,FPS,動画の長さ,ガイダンススケールぐらいかも.
%mkdir /tmp/Text2Video-Zero/outputs
#model.pyを再読み込み(model.pyは頻繁に修正する可能性があるが,再読み込みしないと修正が反映されない)
%cp /tmp/Text2Video-Zero/model.py /notebooks/ #model.pyをnotebooksディレクトリにもってくる.
import model
from importlib import reload
reload(model)
import torch
from model import Model
model = Model(device = "cuda", dtype = torch.float16)
#メインプロンプト(キャラクターの動作を記述する)
prompt = "asuka langley running on a load"
#追加のプロンプト(best qualityなどの修飾)
added_prompt = "masterpiece, best quality, masterpiece"
#ネガティブプロンプト
negative_prompts = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer difits, cropped, worst quality, low quality, deformed body, bloated, ugly, unrealistic"
#hugging faceのリポジトリの指定(例えばSD1.5であれば,"runwayml/stable-diffusion-v1-5"を指定する)
model_name=r"andite/anything-v4.0"
#ガイダンススケール(以下の動画を作った時は,7.5だったかも)
guidance_scale=12 #default:7.5
#サンプリングステップ数. t1の値を超えるとエラーになる(というか50以下だとエラーになる).
num_inference_steps=50 #default:50
#出力する動画の名前
out_path = f"./outputs/text2video_{prompt.replace(' ','_')}.mp4"
#その他のパラメータ
fps=10 #FPS default:4
t0= 44 #default:44. 詳細は不明.44の場合,timestepsでは881に相当するらしい.timesteps換算でt1-t0が60の時が,経験的に一番いい感じだったと論文には書いてあった.
t1= 47 #default:47. 詳細は不明.47の場合,timestepsでは941に相当するらしい.
motion_field_strength_x = 12 #default:12. the globalscene and camera motionのパラメータらしい.が,motionの大きさに関連している?
motion_field_strength_y = 12 #default:12
video_length=8 #default:8. 動画の長さ
# 動画の生成
model.process_text2video(prompt,model_name,added_prompt,negative_prompts,guidance_scale,num_inference_steps,out_path,fps, t0, t1, motion_field_strength_x, motion_field_strength_y, video_length)
# ダウンロードしたモデルの場所は以下のコマンドで確認.
# find / -name "*model.safetensors"動画が生成できたら,ダウンロードしやすい場所にコピーする.
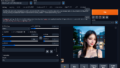
!cp -r /tmp/Text2Video-Zero/outputs /notebooks得られた動画
上記のコードで得られた動画は以下である.model.pyにおいて,seed値は-1に固定しているので,内容はランダムで変わると思う.

プロンプトを”a girl running on a seaside”として,video_length=64にすると以下の感じになった.

プロンプトを”a dog running on a seaside”として,video_length=64にすると以下の感じになった.犬が空中に浮いてる.

FILMで補間してみた
FILM(Frame Interpolation for Large Motion)というフレーム間補間のアルゴリズムで動画を処理してみた.使い方は後日掲載する(こちらの記事).
パラメータを最高値にしたら,1秒未満だった動画が4分の動画になってしまった.スローモーションすぎたので,ffmpegを用いて以下のコマンドで30倍速の動画を作成した.
ffmpeg -i 入力動画ファイル.mp4 -vf setpts=PTS/30 -af atempo=30 保存先/出力動画ファイル.mp4以下が得られた動画である.一歩目までは,人が走ってるアニメっぽい.

まとめ
テキストから動画を生成してみた.フレーム間の一貫性はある気がする.
ただ,動きが滑らかでなく,動きのバリエーションが少ない気がするので,改善の余地が色々ある感じがする.
FILMと組み合わせることには可能性を感じた.右足の一歩目だけ.
コメント