はじめに
FlexGenとかいう,軽量版ChatGPTみたいなのが出たので遊んでみた.
いずれAI (on Google Colab) vs. AI (on Paperspace Gradient)を実現したいので,まず会話内容を渡すインタフェースを検討した.サーバーとかを設定するのもかったるいので,Googleスプレッドシートの入力を監視し,その入力をpromptに渡すことで対話できるようにした.
FlexGenのGithubリポジトリ:https://github.com/FMInference/FlexGen
ちなみに無料の枠のT4だと,一番小さいモデルのfacebook/opt-1.3bですら,メモリエラーで動かなかった.
環境
・Win10 PC
・Google Colab (クレジットが余ってたので,A100.T4だとできなかった.)
・使用したFlexGenのモデルは,opt-6.7b
Googleスプレッドシートを作成し,ファイルIDをメモ
Googleスプレッドシートを作成し,ファイルIDをメモする.IDの位置は,スプレッドシートを開いた時に表示されるURLの以下の部分.
https://docs.google.com/spreadsheets/d/ここがファイルID/edit#gid=0FlexGenのインストール
このブログ(https://zenn.dev/ik/articles/4d8cc9729635d7)を参考にインストールした.以下のコードを挿入し実行する.
# Googleドライブのマウント
from google.colab import drive
drive.mount("/content/drive")# 作業フォルダの作成と移動
import os
os.makedirs("/content/drive/MyDrive/FlexGen", exist_ok=True)
%cd "/content/drive/MyDrive/FlexGen"# HuggingFaceのキャッシュパスの設定
import os
os.environ['TRANSFORMERS_CACHE'] = '/content/drive/MyDrive/FlexGen'
os.environ['HF_DATASETS_CACHE'] = '/content/drive/MyDrive/FlexGen/Datasets'次にインストールだが,ブログに「最新のものはリファクタリング中のものもあるため、特定のcommitにresetします。」と記載があるが,これが大切で,FlexNetのバージョンが変わるとファイルの名前が変更されていたりするので,この操作はした方が良い.
# FlexGenのインストール
!git clone https://github.com/Ying1123/FlexGen.git
%cd "/content/drive/MyDrive/FlexGen/FlexGen"
!git reset --hard f79b895
!pip install -e .その後,ディレクトリを移動する.上記のセルを実行したフォルダ構成の場合は,以下のように「/content/drive/MyDrive/FlexGen/FlexGen/」ディレクトリに移動する.
%cd /content/drive/MyDrive/FlexGen/FlexGen/この操作は,以下のコードでpythonのモジュールを正常にインポートするために必要になる.
Googleスプレッドシートを介して対話できるようにコードを修正
今回はGoogle Colabの機能を使ってスプレッドシートにアクセスしている.認証がブラウザ上でできるメリットはあるが,pyファイルで実行することはできないので,ipynb上で実行できる仕様に変更した.apps/chatbot.pyファイルを元に作成した.
主に実施した内容としては,Googleスプレッドシートにアクセスし,奇数行にある人間からの質問内容を読み込めるように変更したことである.ポーリングによりスプレッドシートに変更があるかを監視して,変更があればその内容をAI(FlexGen)に渡している.その後,AIからの回答はスプレッドシートの偶数行に格納している.
監視のために頻繁にAPIを呼び出してしまうと,Google スプレッドシートAPIのリクエストの上限(300リクエスト/分ぐらい?)に引っかかるので,time.sleepを入れて待つことにした.⇒上限について(参考サイト):https://www.cdata.com/jp/blog/2019-04-16-191006
セルの停止ボタンで終了すると,再度セルを実行した際にタイマー関連のエラーが出るようになり,ランタイムを再起動する必要が生じてしまうので,確実に終了文字(今回の例では「Finish」)で終えること.
以下のセルを追加した.色々いらない部分もあるかもしれないが,とりあえずはこれで動いた.コードの“スプレッドシートのファイルID”の箇所を先ほどメモしたIDに変更すれば動くと思う.
from zmq.constants import NOBLOCK
"""Run a chatbot with FlexGen and OPT models."""
from transformers import AutoTokenizer
from flexgen.flex_opt import (Policy, OptLM, TorchDevice, TorchDisk, TorchMixedDevice,
CompressionConfig, Env, Task, get_opt_config, str2bool)
def main():
# パラメータ設定.元のコードでは,コマンドライン引数で渡すものをここで設定する.
offload_dir="~/flexgen_offload_dir"
percent=[100, 0, 100, 0, 100, 0]
model="facebook/opt-6.7b"
path="~/opt_weights"
compress_weight=False
pin_weight=True
compress_cache=False
# percentの仕様.以下の割合を調整する(0~100).
# "the percentage of weight on GPU, "
#"the percentage of weight on CPU, "
#"the percentage of attention cache on GPU, "
#"the percentage of attention cache on CPU, "
#"the percentage of activations on GPU, "
#"the percentage of activations on CPU
#pin_weightの仕様
#重みを固定するかどうか(Falseに設定するとCPUメモリが20%減少するらしい)
#compress_weightの仕様
#重みを圧縮するかどうか.
# Initialize environment
gpu = TorchDevice("cuda:0")
cpu = TorchDevice("cpu")
disk = TorchDisk(offload_dir)
env = Env(gpu=gpu, cpu=cpu, disk=disk, mixed=TorchMixedDevice([gpu, cpu, disk]))
# Offloading policy
policy = Policy(1, 1,
percent[0], percent[1],
percent[2], percent[3],
percent[4], percent[5],
overlap=True, sep_layer=True, pin_weight=pin_weight,
cpu_cache_compute=False, attn_sparsity=1.0,
compress_weight=compress_weight,
comp_weight_config=CompressionConfig(
num_bits=4, group_size=64,
group_dim=0, symmetric=False),
compress_cache=compress_cache,
comp_cache_config=CompressionConfig(
num_bits=4, group_size=64,
group_dim=2, symmetric=False))
# Model
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-30b", padding_side="left")
tokenizer.add_bos_token = False
stop = tokenizer("\n").input_ids[0]
print("Initialize...")
opt_config = get_opt_config(model)
model = OptLM(opt_config, env, path, policy)
model.init_all_weights()
context = (
"A chat between a curious human and a knowledgeable artificial intelligence assistant.\n"
"Human: Hello! What can you do?\n"
"Assistant: As an AI assistant, I can answer questions and chat with you.\n"
"Human: What is the name of the tallest mountain in the world?\n"
"Assistant: Everest.\n"
)
# 認証のためのコード
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
# スプレッドシートを指定し,先頭のワークシートをオープン
worksheet = gc.open_by_key('スプレッドシートのファイルID').get_worksheet(0)
import time
val=0
prompt=""
# Chat
print(context, end="")
now_last_index=0
target_index=1
while True:
#A列のデータを配列として取得
a_col_array = worksheet.col_values(1)
now_last_index = len(a_col_array)#個数
print(now_last_index)
# 返信が来る予定の行番号になっていない限りは,ループを抜けない
while(now_last_index!=target_index):
time.sleep(0.5)# APIに頻繁にアクセスすると,上限に引っかかり停止するので待つ.300リクエスト/分ぐらいが上限.
a_col_array = worksheet.col_values(1)
now_last_index = len(a_col_array)
if now_last_index != 0:
inp=worksheet.cell(now_last_index,1).value
if inp=="Finish":
print("exit...")
break
#こっちは偶数用
# if now_last_index%2==1:
time.sleep(0.5)# APIに頻繁にアクセスすると,上限に引っかかり停止するので待つ.300リクエスト/分ぐらいが上限.
prompt=worksheet.cell(now_last_index,1).value
print(prompt)
# inp = input("Human: ")
print("人間:",end=' ')
print(prompt)
inp = prompt
if inp=="Finish":
print("exit...")
break
context += "Human: " + inp + "\n"
inputs = tokenizer([context])
output_ids = model.generate(
inputs.input_ids,
do_sample=True,
temperature=0.7,
max_new_tokens=96,
stop=stop)
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
try:
index = outputs.index("\n", len(context))
except ValueError:
outputs += "\n"
index = outputs.index("\n", len(context))
outputs = outputs[:index + 1]
print(outputs[len(context):], end="")
message=outputs[len(context):].lstrip("Assistant:")#返信の格納. Assistant:の文字列はいらないので削除.
time.sleep(0.5)# APIに頻繁にアクセスすると,上限に引っかかり停止するので待つ.300リクエスト/分ぐらいが上限.
worksheet.update_cell(now_last_index+1,1,message )#行,列.セルの書き込み
target_index=target_index+2
context = outputs
# TODO: optimize the performance by reducing redundant computation.
# Shutdown
model.delete_all_weights()
disk.close_copy_threads()
if __name__ == "__main__":
main()
実行結果(動画)
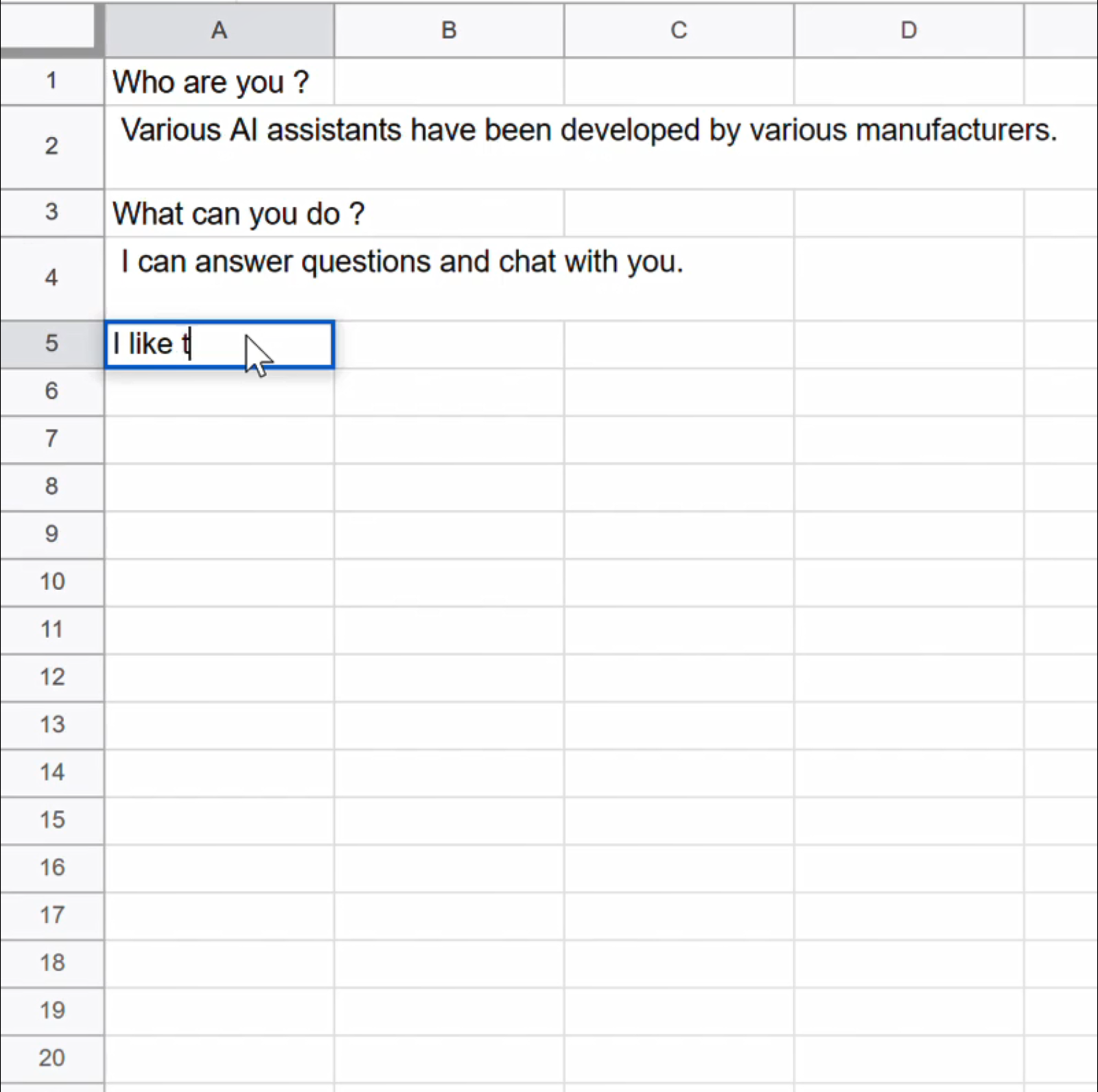
全てのセルを実行して以下の画面になったら,入力を受け付け可能な状態である.

その後,質問をスプレッドシートに入力する.今回のプログラムでは,奇数のセルが人間で,偶数のセルがAIである.人間が奇数セルに質問を書き込むと,返信が返ってくるので対話できる.
まとめ
とりあえず,Googleスプレッドシートというインタフェースを介して,FlexGenと対話することができた.
あとは今は人間が入力している箇所をAIに置き変えれば良いのだが,Paperspaceは容量が少ないので学習済みデータをどうするか迷っている(AUTOMATIC1111ほどシンプルではなかったので).今回使用したモデル”opt-6.7b”であれば12GBほどなのでギリギリ入るか・・・.
⇒tmpに入れたら,容量食わずにできたが,VRAMかRAMの問題で結局opt-1.3bしか使えなかった(記事).
あと,AIどうしの早い入力だとバグるみたいなので,処理の仕方を変えた方が良さそう.

コメント